GPT-4o vs Claude Sonnet in Max accuracy mode — welfare scores, peer review, preference memory
Use it as a powerful context manager — search months of conversations, resume any project instantly, never re-explain your preferences. Or use it to run multiple AI models simultaneously and let mechanism design pick the best answer. Both, always on.
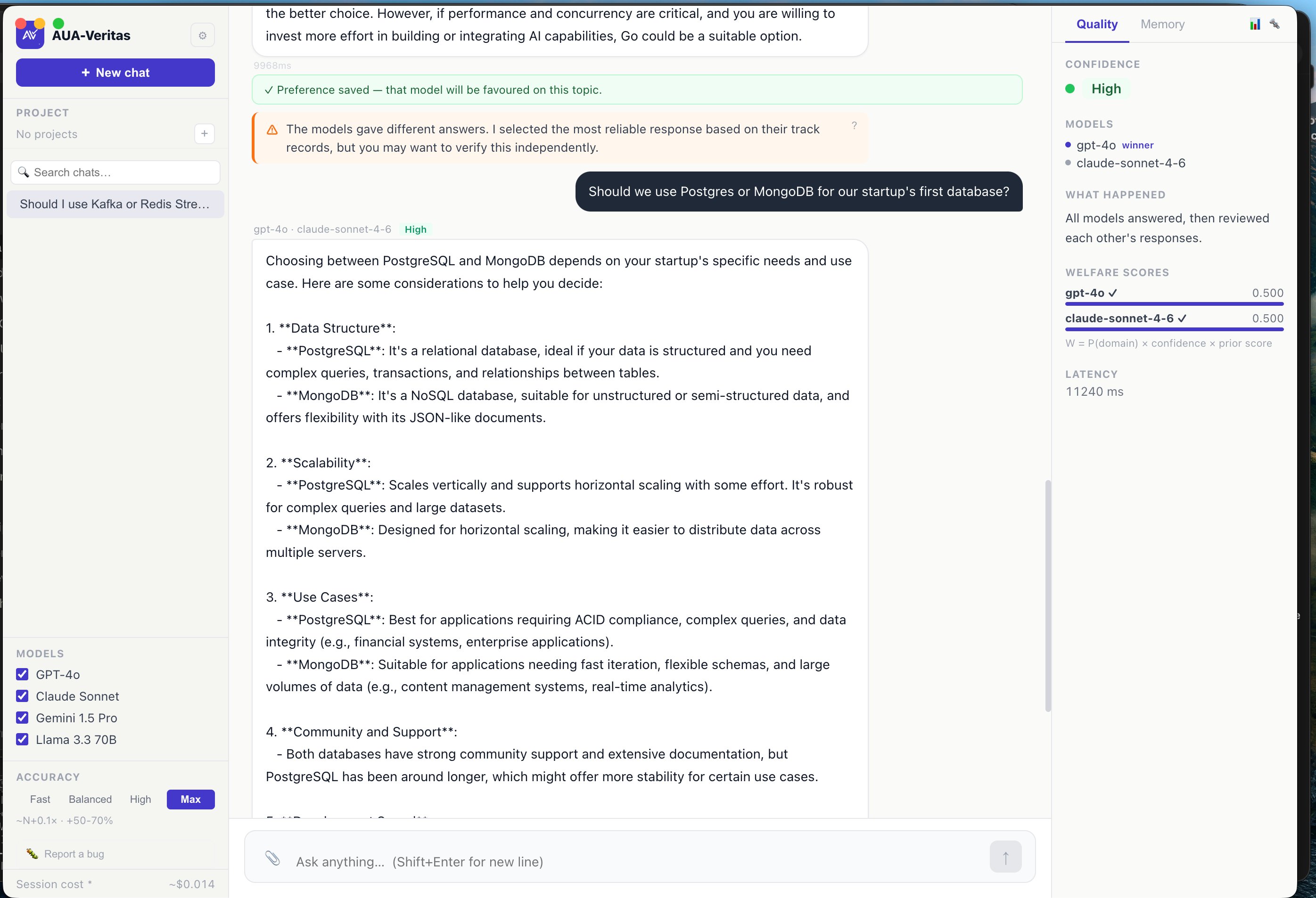
GPT-4o vs Claude Sonnet in Max accuracy mode — welfare scores, peer review, preference memory
You only need one API key to start. Add more later to unlock multi-model comparison.
macOS
Mount DMG → drag to Applications → run in Terminal:
xattr -cr /Applications/AUA-Veritas.app
ℹ If macOS asks "wants to accept incoming network connections" — click Allow. The app runs a local server on your machine so the interface and backend can talk to each other. It does not expose anything to the internet.
Linux
chmod +x AUA-Veritas-*.AppImage
./AUA-Veritas-*.AppImage
Windows
Run AUA-Veritas Setup 0.9.0.exe → launch from Start menu
Open Settings ⚙ and paste your key. One key is enough to start — add more to unlock multi-model comparison.
Ask anything. Use High or Max accuracy for important questions to see multiple models compete. Correct an answer once — Veritas remembers it forever.
Leave a project for three months. Come back, type a follow-up, and the AI already knows your stack, your preferences, your previous decisions — without you re-explaining anything.
Every conversation is fully keyword-indexed. Search across months of work in milliseconds. Find that architecture decision, the code snippet you wrote last Tuesday, the reason you chose Postgres over MongoDB.
Every frontier model has blind spots. Veritas runs all of them on every query and uses a game-theoretic mechanism to pick the winner — turning competition into correctness.
Each layer adds correctness. Together they form a self-improving system that compounds over time.
Before every query, Veritas scores all stored corrections and preferences against the current question using 8 factors: relevance, importance, recency, confidence, staleness, and more. Only corrections above a threshold are injected — no token waste.
All enabled models answer simultaneously. Each reports its self-assessed domain using a DOMAINS: tag. A domain-decomposed Vickrey–Clarke–Groves welfare function scores each model: W_i(q) = Σ p(j|q) · u_i(j) where u_i(j) is the model's volume-normalized win rate in domain j.
When models disagree, a separate reviewer model checks the winner's answer for accuracy. Correct → reward. Incorrect → correction stored. You can always override by picking any model's answer — that preference is recorded and shifts future routing.
When you reply with something like "No, it's 53" or "I prefer metric units", Veritas detects the implicit correction using a semantic similarity model. You're asked to confirm, then it's stored permanently and injected on all future relevant queries.
A compliance monitor checks every response against active instructions. If a model stops following a rule for 2+ consecutive responses, the next system prompt reinforces it in bold. The domain tree grows automatically from model self-reports — no manual taxonomy needed.
Use it as a powerful AI assistant with multi-model verification, or simply as the AI that never forgets your context. Both modes are always on.
Corrections, preferences, and domain-specific rules survive across sessions. The system never forgets what you've taught it.
Game-theoretically optimal model selection — models are incentivised to report their true domain competencies, not just sound confident.
Domains grow naturally from model self-reports. "constitutional law" and "molecular biology" become their own nodes when data justifies it.
Every decision is visible: decision chain, welfare scores, peer review verdict, confidence calibration, domain routing, correction history.
All data stays on your Mac. Encrypted SQLite database. No telemetry, no cloud sync, no vendor lock-in. Your API keys, your data.
Backend binary launches in milliseconds. WAL-mode SQLite for all DB operations. Cache pre-warm on startup. Instant on return.
Run Ollama models alongside frontier models. Tag local models as domain specialists — they compete on equal footing in VCG elections.
One click to report a bug. Goes directly to a private repo. Anonymous machine token — no personal data unless you opt in.
Real-time per-model token pricing. Session cost tracked to three decimal places. No surprises on your API bill.
Everything about how AUA-Veritas works — from the database schema to the VCG mechanism, domain ontology, and architecture decisions.
Multi-model VCG routing, welfare scoring, correction memory, context backup system, domain ontology. Full technical design.
All 17 SQLite tables — conversations, messages, model_runs, corrections, backups, search index, domain ontology — every column and index.
Step-by-step guide to getting the most out of AUA-Veritas: accuracy modes, corrections, projects, context backups, local models.
Design log, VCG domain utility analysis, phase 12 domain ontology, compliance monitor, context manager test suite, and more.
The open-source framework powering AUA-Veritas. Build your own adaptive multi-model LLM system. Django-style, batteries included.
What was built, what's next, and the lessons learned from shipping AUA-Veritas to production — including Phase 13 backport items.
Download the latest .dmg from GitHub Releases. Mount, drag to Applications, right-click → Open to bypass Gatekeeper on first launch.
Click the ⚙️ Settings icon. Add keys for any combination of OpenAI, Anthropic, Google, and Groq. You only need one — but more models means better VCG elections.
Start chatting. Use Balanced mode for everyday queries, High or Max for anything important. Corrections are stored automatically — the system learns from every interaction.